Voice Cloning Using Transformer Based TTS and Embedding Tuning.

Have you ever wished you could clone someone's voice? Maybe you wanted to impersonate a celebrity or create a personalized voice assistant for yourself. Thanks to advances in machine learning, this is now possible through a technique called "voice cloning."
Voice cloning is the process of creating a synthetic voice that sounds like a specific individual. It involves training a machine learning model on audio samples of the target voice and then generating new audio using that model. Voice cloning has numerous applications, including entertainment, customer service, and accessibility.
In this blog post, we'll explore how a transformer-based model and embedding tuning can be used to create a voice cloning project. We'll cover the steps involved, from selecting a dataset and training the model to fine-tune the embeddings and generating new audio samples. We'll also provide some sample audio files to demonstrate the capabilities of voice cloning.
Previous Approaches
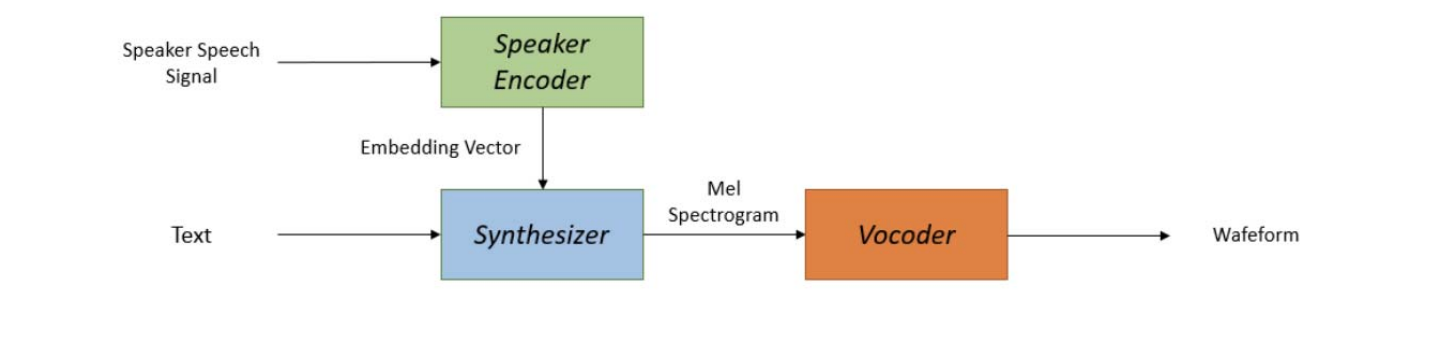
Multi-speaker text-to-speech synthesis can be achieved using a transfer learning system consisting of three components: a speaker-encoder, a synthesizer, and a neural vocoder. The speaker-encoder generates an embedding vector from a short reference speech sample, which is then used by the synthesizer to produce a Mel spectrogram. The vocoder converts the spectrogram into time-domain waveforms.
During inference, the speaker-encoder creates the embedding vector based on the target speaker's learned characteristics. The synthesizer generates the mel-spectrogram using the input text and the speaker-encoder's embedding vector, and the vocoder produces the final speech waveform. A neural network model is trained on a text-independent speaker verification task using the GE2E loss to optimize the approach, ensuring that same-speaker embeddings have high cosine similarity while different-speaker embeddings are separated in the embedding space.
However, this approach has some limitations. For instance, since it uses a pre-trained network to extract embeddings from a single utterance, it may leak data about emotions into the embeddings due to the GE2E loss. Additionally, there is no possibility to fix some embeddings during inference if any issues arise.
New method
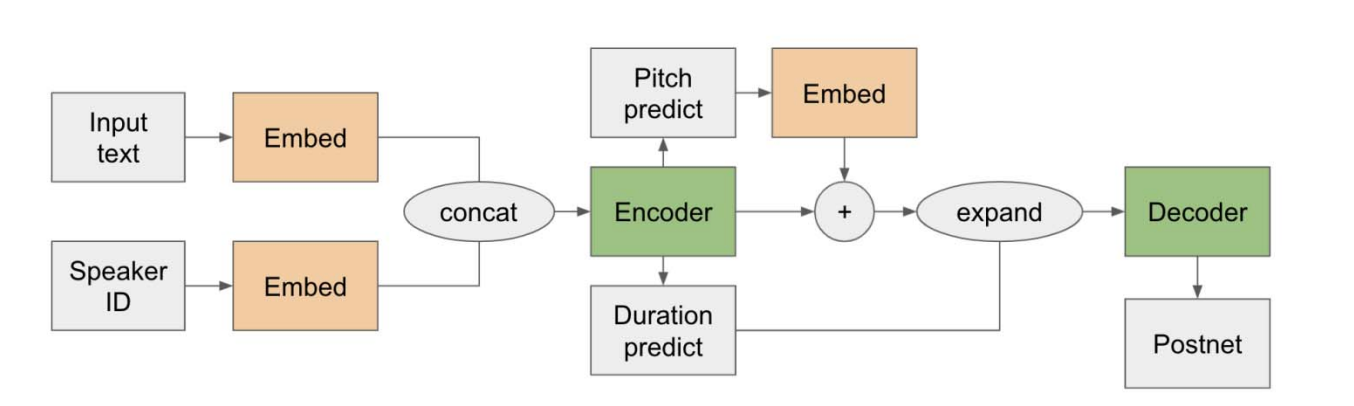
To address the limitations of the existing approach, a possible solution is to create a multi-speaker text-to-speech system with trainable embeddings. For new speakers, random embeddings can be fine-tuned to learn their unique characteristics. This would avoid the use of pre-trained networks and enable more control over the embeddings, potentially resulting in better preservation of emotional content.
The system described in Figure 2 serves as the foundation for our approach. It is comprised of a stack of Multi-Head Attention Transformer blocks, which are used for both the Encoder and Decoder. The Encoder and Decoder are each composed of Self-Attention-Dense Blocks (SADB) followed by Self-Attention-Conv Blocks (SACB). The use of this model allows us to generate speech in more than 800 different voices, with a Mean Opinion Score (MOS) higher than 4.1. The high MOS score demonstrates that this system is capable of producing speech that is not only diverse but also of high quality.
Through experimentation, we discovered that we could generate speech with the voices of unseen speakers by selecting a random vector from the speaker embedding space or combining several speaker embeddings using methods such as sum, mean or max pooling. This led us to the idea that we could find an embedding for every new unseen voice. The key to this process lies in generating an embedding for a new speaker who has only a few minutes or seconds of target speech. We achieve this by training only the embedding for a few iterations, resulting in a well-performing embedding for that particular speaker. This technique allows us to expand the number of voices our system can synthesize, enabling it to generate speech for speakers not originally included in the training data.
The sentence "In some amphibious aircraft, the single-engine is mounted on a pylon attached to the fuselage, which in turn is used as a floating hall" was used to generate examples of unseen speaker voices, using the VCTK dataset. Below, you can find some of the resulting samples.
It's worth to mention there are already several existing voice cloning tools available, such as Murf, Resemble, Podcastle, and Overdub. These tools use a variety of techniques, including deep learning, to create synthetic voices that sound like specific individuals. However, in our experience, one of the most impressive voice cloning tools available today is ElevenLabs. What sets ElevenLabs apart is the quality of the cloned voice - it sounds incredibly natural, and only a few seconds of audio are required to create a convincing clone. I was able to create synthetic versions of Venom's voice from the movie "Venom" and Sir Christopher Lee's voice, using only a short 3-4 second clip of each. The results were impressive - the cloned voices sounded great and highly realistic.
References
[1] FastPitch: Parallel Text-to-speech with Pitch Prediction.
[2] Generalized End-to-End Loss for Speaker Verification